TensorFlow & Kerasのこと初め
- 記事の目的
- TensorFlow basics
- Keras
- The Sequential model
- The Functional API
- Introduction
- Training, evaluation, and inference
- Save and serialize
- Use the same graph of layers to define multiple models
- All models are callable, just like layers
- Manipulate complex graph topologies
- Shared layers
- Extract and reuse nodes in the graph of layers
- Extend the API using custom layers
- When to use the functional API
- Mix-and-match API styles
- まとめ
- Training and evaluation with the built-in methods
- Introduction
- API overview: a first end-to-end example
- The compile() method: specifying a loss, metrics and an optimier
- Training & evaluation from tf.data Datasets
- Other input formats supported
- Using a keras.utils.Sequence object as input
- Using sample weighting and class weighting
- Passing data to multi-input, multi-output models
- Using Callbacks
- Checkpointing models
- Using learning rate schedules
- Visualizing loss and metrics during training
- まとめ
- Making new Layers and Models via subclassing
- Save and load Keras models
- Working with preprocessing layers
- Customize what happens in Model.fit
- Writing a training loop from scratch
- 終わり
記事の目的
この記事はTensorFlowとKerasを初めて使う人のために基本的な事項について解説します。主に
- 主要なクラス
- 各クラスの相互関係、優劣、使い分け
などを解説します。
メインとしてTensorFlow Guideを解説していきます。
本当に基礎的となるクラスの理解を目指していますので、かなり多くの記述を省いていて、コード例もほとんど載せていません。適宜公式のドキュメントを参照していただければと思います。
僕自身、TensorFlowとKerasを扱うのが初めてで、その時に感じた疑問を解消するように記事をまとめたので、同じような人に対して有益な情報を提供できればと思います。
また、事前知識としては以下の本を読んでいます。
こちらの本はサンプルコードなどは非常に参考になりますが、この本を読んでもわからなかった箇所を理解しようと思い、今回この記事をまとめようと思いました。
TensorFlow basics
Eager execution
Eager executionとはTensorFlow 2からの機能らしいです。
僕は1を使ったことがないので2との違いが把握できていません。そのため、Eager executionについてはまだ把握しきれていない部分もありますのでここの解説はやや自信がありません。ご了承ください。
Eager executionの特徴として以下のようなものがあります(ここはまだ自分でも理解しきれていません):
- 直感的なインターフェースがあります。Pythonのデータ構造を使うことができ、小さいモデルを少ないデータで直ぐに繰り返すことができます。
- デバッグが簡単になります。ops(モデルの演算などのことだと思われます)を直接呼び出して、実行中のモデルを検査し、変更のテストをします。Pythonのデバッグツールも使用することができます。
- グラフの制御フローの代わりにPythonの制御フローを使用することができます。
Setup and basic usage
eager executionが有効になっていると、tf.Tensorはgraphのnodeへのsymbolic handleでは無くの実際の値を参照します。そのため、print()やデバッガによって値を簡単に調べることが可能になります。
eager executionはNumPyのオブジェクトなどともうまく連携する仕組みを提供します:
- NumPyの演算は
tf.Tensorも扱えます。 tf.mathはPythonのオブジェクトとNumPy arrayをtf.Tensorに変換して計算します。tf.Tensor.numpyはTensorの値をNumPyndarrayで返します。- 演算のブロードキャストもサポートします。
Dynamic control flow
Pythonの機能も使用することができます。例えば、比較演算子などで数値の比較を行うこともできます。
Eager training
ここで解説しているものは、それぞれ別の章で改めて解説しているのでこの場で読む必要はないと思われます。
Advanced automatic differentiation topics
ここで解説しているものも改めて別の章で解説されるのでここで読む必要はないと思われます。
Performance
eager executionでは演算は自動的にGPUに処理させます。ただし、演算を実行するデバイス(CPUやGPUなど)を指定して実行することもできます。
また、tf.Tensorは演算するためにデバイス間でコピーすることができます。
Benchmarks
特定の状況でのトレーニングではeager executionとtf.functionでの実行は同程度の性能があります。ただし、状況によっては性能差が大きくなっていくらしいです。
Work with functions
eager executionはメリットもありますが、graph executionと比べると
などで不利な点があります。
このギャップを埋めるのがtf.functionです。
詳しくは、tf.function guideを参照してください。
まとめ
eager executionを僕なりに重要だと思ったところをまとめると、
- インタラクティブな実行環境を提供している
- eager executionと対になる概念としてgraph executionがある
- それを橋渡ししているのが
tf.functionになる
になります。 TensorFlowの全体像を掴む上ではこれを押さえておくと見通しが良くなります。
Tensor
tensorは多次元配列で、
- 全ての要素が同じ型(
dtypeと呼ばれる) np.arraysに似ている- immutableである。つまりアップデートはできず、常に新しいtensorが作成される
ような特徴を持っています。
Basics
ここでは
tf.constantによるtensorの作成方法tf.tensor.numpy()メソッドによるnp.arrayへの変換- tensorごとの演算
- operations (ドキュメントでopsと呼ばれるのはここで紹介されているような演算の総称のことのようです)
の紹介がされています。
About shapes
ここではtensorの形状についての説明がありますが、NumPyを知っていればほとんど問題ありません。
ただ、tensorの各次元へのデータの入れ方の順序は意識していたほうがいいかなと思いました。末尾の次元から特徴量、先頭の次元ではバッチのまとまりのように帯域的なデータのまとまりを保存するようです。
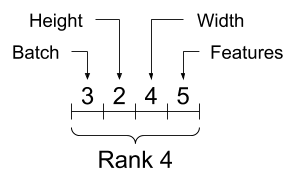
Indexing
ここもNumPyの知識があればほとんど問題ありません。
Single-axis indexing
Multi-axis indexing
Manipulation shapes
ここもNumPyの知識があればほとんど問題ありません。
ただ、次元の転置をするときはtf.reshapeでは行えませんので、tf.transposeを実行する必要があります。
More on DTypes
tv.cast関数を使ってdtypeを変えられるよというお話です。
Broadcasting
tensor同士の演算のbroadcastの話です。 ここもNumPyの知識があればほとんど問題ありません。
tf.convert_to_tonsor
大体のopsはtensorではない引数に対してtf.convert_to_tensor関数を呼び出してtensorに変換するのでtensorではない引数もopsで計算できてしまうようです。
Ragged Tensors
通常のtensorでは以下のような構造のtensorを作成することができません。
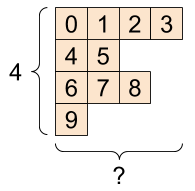
このように、ある次元の長さが不規則なtensorを作成するためにtf.RaggedTensorというクラスがあります。
String tensors
文字を扱うtensorもありますが、TensorFlowの概要を理解するのには後回しでいいでしょう。必要になったら戻ってきましょう。
Sparse tensors
以下のように、一部にしかデータが入っておらず、他は0のようなtensorを扱うためにsparse tensorがあります。
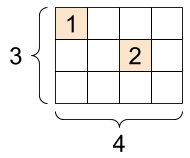
メモリの効率が良かったりするのでしょうか?
まとめ
tensorは大体NumPyのndarrayと思っておけば大丈夫そうです。もっと細かい調整が必要なら詳しく調べてみるくらいのスタンスで初めはいいのではないでしょうか。
Variable
variableはtf.Variableクラスのオブジェクトで、
- opsを実行することで値を更新することができるtensorと考えられる。値を更新することができないtensorとは対照的。
tf.kerasなどの高レベルのライブラリはモデルのパラメータをtf.Variableを使って管理する
のような特徴があります。
Create a variable
variableは
my_tensor = tf.constant([[1.0, 2.0], [3.0, 4.0]]) my_variable = tf.Variable(my_tensor)
のように作成します。
variableはtensorと同じようなメソッドも使えます。ただし、reshapeは新しいtensorを作り出し、元のvariableは更新されません。
また、以下のようにvariableから新しいvariableを作成した際に、bには新しいメモリが割り当てられて、aとメモリを共有していません。ハードコピーというイメージでいい気がします。
a = tf.Variable([2.0, 3.0]) # Create b based on the value of a b = tf.Variable(a)
Lifecycles, naming, and watching
variableには名前をつけることもできます。
特に、モデルのなかのvariableは保存、読み込み時に名前が保たれます。モデルの中のvariableの名前は一意である必要がありますが、モデルの作成時に自動的に割り当てられるらしいので特に意識する必要はありません。
モデルの中には訓練する必要のないvariableも存在します。そのようなvariableはtrainable=Falseを指定して作成します。
Placing variables and tensors
CPUで計算するかGPUで計算するかなどのお話です。TensorFlowの概要を理解するのには飛ばしていいでしょう。必要になったら戻ってきて理解しましょう。
まとめ
variableとは
- 更新可能なtensorのようなもの
- 特に、Kerasなどではmodelのパラメータにvariableが使われている
- 訓練の必要がないvariableには
trainable=Falseを指定する
です。
Automatic differentiation
この章はTensorFlowの概要を理解するためにはやや高度な話も含まれていたので結構省略してまとめています。
Gradient tapes
TensorFlowは自動微分を計算するためにtf.GradientTape というAPIを用意しています。
tf.GradientTape コンテキスト内で実行される演算を”テープ”に記録し、これらを使って逆伝搬により微分を計算します。
詳しい使い方はサイトを参照してください。
Gradients with respect to a model
tf.Modelを使った演算の自動微分も計算することができますよとのことです。
tf.Modelは別の章で解説されます。
Controlling what the tape watches
自動微分のデフォルトの挙動は訓練可能なtf.Variableにアクセスした後にopsの記録をします。これは
- テープは逆伝搬で微分を計算する際に、どのopsを順伝搬に記録するかを知る必要がある
- 中間出力を保持する必要のないopsがある
- 最も一般的な使い方が、trainable variableに関するモデルの損失の微分を計算することである
のような理由からだそう。
微分が計算できないものとして
tf.Tensortrainable=Falseとなっているtf.Variable
があります。
ただし、tensorの微分を計算するために、GradientTape.watch(x)メソッドが用意されています。
まとめ
tf.GradientTapeは基本的にはtf.Variableの微分を計算するものとひとまず覚えておきましょう。詳しい使い方は少しずつ覚えていきましょう。
Intro to graphs and functions
Overview
What are graphs?
今までの解説はeager executionのもとで実行していました。
eager executionと対になる概念としてgraph executionがあります。graph executionは
- Python以外へのデプロイが可能
- より良いパフォーマンス
などの特徴があります。
graph executionとはtensorの計算をtf.Graphとして実行することです。(そのまんまですね・・・)
graphとはtf.Operationとtf.Tensorをまとめたデータ構造のことです。
The benefits of graphs
graphの利点として、
- saved modelsによりPython以外の環境へエクスポートすることができる
性能面として
- 定数ノードをfoldingすることでtensorの値を静的に解析する(知識不足のため理解できていません・・・)
- 独立した計算を別々のスレッドやデバイスに分割する
- 共通している部分式を削除することで算術演算を簡素化する
などがあります。簡単にいうと、graphはTensorFlowの実行を高速化、並列化します。
Taking advantage of graphs
graphはtf.functionを使って作成します。もしくは、関数定義時にtf.functionをデコレータとして使用することで作成できます。
Converting Python functions to graphs
関数定義にif-then、ループ、breakなどなどのPython構文が含まれている関数をgraph化する際には追加の処理が必要になる可能性があるそうです。
大抵の場合はあまり気にすることはないそうですが、より詳細にはtf.function guideとcomplete AutoGraph referenceを読むと良いそうです。
Polymorphism: one Function, many graphs
一つのFunctionでも、引数のdtypeとshapeごとに新しいtf.Graphを内部的に作成します。各tf.Graphのdtypeとshapeのことをinputo signatureとかsignatureと呼ぶそうです。このように、dtypeとshapeごとにtf.Graphを作成することで最適化されるようです。
Using tf.function
tf.functionをただ使用するだけでgraphを作成できますが、いくつか注意する挙動をここでは紹介しています。
Graph execution vs. eager execution
細かい話なのでリンク先参照でいいでしょう。graphが新しく作成される際のtraceという処理はパフォーマンスの点で重要になります。
tf.function best practices
想定通りにgraph化するためのベストプラクティスとして以下のようなものがあります:
- eager executionとgraph executionを頻繁に切り替えて動作に違いがないかを確認する。
tf.Variableの作成はPythonの関数定義の外側で行い、変更を関数内で行う。これはkeras.layer、keras.Model、tf.optimizerなどにも当てはまる。tf.VariableとKerasのオブジェクト以外に、外部のPython変数に依存する関数を作らない。- 引数はtensorやその他のTensorFlowのオブジェクトにする。それ以外を引数にする際には注意する。
- パフォーマンスの面から、なるべく多くの計算を
tf.functionにまとめる。
Seeing the speed-up
高速化の実例があります。リンク先参照してください。
Performance and trade-offs
graphの作成によるtraceのオーバーヘッドが酷いとパフォーマンスに影響がありますよという話です。
When is a Function tracing?
traceは引数に渡すpythonのオブジェクトが変わるだけで実行されるので注意というお話です。
まとめ
graph executionの特徴として
- Python以外の環境へデプロイすることができるようになる
- eager executionよりもパフォーマンスが良い
- input signature毎に新しいgraphが作成される
- traceのオーバーヘッドによるパフォーマンスの低下に気をつける
を覚えておきましょう。
Intro to modules, layers, and models
modelとは
もののことです。
Defining models and layers in TensorFlow
modelのほとんどはlayerから作られています。layerは再利用可能で、トレーニング可能なvariableを持つ関数です。(再利用可能のニュアンスが不明です・・・)Kerasなどの高レベルのlayerの実装はtf.Moduleのサブクラス化で作られています。
tf.Moduleをサブクラス化した場合、tf.Variableなどは自動的にこのオブジェクトによって収集されて、トレーニングなどにより更新できるようになります。tf.Variableだけではなく別のtf.Moduleのtf.Variableも同様に収集されます。つまり、tf.Moduleはネストできるということです。
Waiting to create variables
特徴量の数が正確に定まっていない時など、入力するtensorの形状が定まっていない場合に、modelの作成時に入力tensorの形状を保留することができるようなこともできますよというお話。
Saving weights
tf.Moduleは保存機能もあるよというお話。
ここではcheckpointという機能を使ってmodelのweight (トレーニングしたvariable)の保存を紹介しています。
Saving functions
Creating a SavedModel
graph化しておけばtf.saved_model.saveを使ってシリアライズすることができますというお話です。
Keras models and layers
Keras layers
tf.keras.layers.Layerはtf.Moduleを継承していて、全てのKeras layerの基底クラスになっています。
tf.keras.layers.Layerを継承するときは__call__をcallにするだけでtf.Moduleの継承と同じように使用することができます。
The build step
入力する特徴量の数をクラスの定義時には定めなくても良くなる仕組みとしてbuildメソッドがあります。
Keras models
tf.keras.layers.Layerよりも機能が豊富なtf.keras.Modelというクラスもあります。使い方はほとんどtf.keras.layers.Layerと同じです。
また、以下のように、関数型を呼び出すようにAPIを使えば、既存のlayerの組み合わせなどのような単純なモデルを作るときは非常に短いコードで作成することができます。
inputs = tf.keras.Input(shape=[3,]) x = FlexibleDense(3)(inputs) x = FlexibleDense(2)(x) my_functional_model = tf.keras.Model(inputs=inputs, outputs=x)
Saving Keras models
Kerasのモデルも保存することができますが、別のところで詳しく解説されているので後でいいでしょう。
まとめ
modelとは
- tensorの計算をする(順伝搬)
- トレーニングに応じてvariableの更新ができる
- ほとんどのmodelはlayerからできている
- layerは訓練可能なvariableを持つ数学的な演算を行う関数のこと
- layerは
tf.Moduleを継承することで作成する - 保存機能もある
- Kerasでもmodelと似たようなものを扱える
- Kerasでは
tf.keras.layers.Layerクラスを継承することでmodelを作成する
のような特徴があります。
Training loops
ここでは、今まで紹介してきたtensor、variable、gradient tapeそしてmoduleを使ってモデルをトレーニングする方法を紹介します。
Solving machine learning problems
機械学習の問題を特には通常以下のステップがあります:
- データの入手
- モデルの定義
- 損失関数の定義
- トレーニングデータからの損失関数の計算
- 損失関数の勾配の計算とモデルの重さのデータへのフィット
- 結果の評価
Data
一次関数に正規分布のノイズが加えられたデータの生成です。
Define the model
tf.Moduleを継承して、variableとtensorの計算をカプセル化します。
Define a loss function
損失関数を定義します。ここではL2損失を定義します。
Define a training loop
ここでは、順伝搬を計算して重みを更新するtrain関数と、各エポック毎に損失と重みの更新を記録するtraining_loop関数を定義して、簡単な機械学習モデルの訓練の例を示しています。
The same solution, but with Keras
上でやってきたことを今度はKerasを使って実装します。
Kerasを使うと
train関数とtraining_loop関数のような、訓練を実行する関数を書く必要がない- その代わり、
compileメソッドとfitメソッドを使えば同じことができる compileはoptimizerと損失関数を設定するfitでエポックとバッチサイズを指定して訓練する
のようになります。非常に簡単に書けます。
まとめ
モデルの訓練にはKerasのcompileとfitを使うと簡単に実装できます。
TensorFlow basicsの残りの部分
TensorFlow basicsのこれ以降の部分はTensorFlowの概要を掴むにはやや高度な部分な気がするので、この後はKerasの説明を読むと良いと思います。実際にmodelを作成し始めたらさらに読んでみると良いと思います。
Keras
The Sequential model
ここではKerasのmodelの作り方のうち、sequential modelと呼ばれる方法を紹介します。sequential modelと対になる方法としてfunctional APIと呼ばれる方法があります。それは次の章で解説します。
When to use a Sequential model
sequential modelは一つのtensorを受け取り一つのテンソルを出力する層の単純な積み重ねになっているmodelの作成に適しています。
sequential modelは以下のようにkeras.Sequentialを使用して作成します。
# Define Sequential model with 3 layers model = keras.Sequential( [ layers.Dense(2, activation="relu", name="layer1"), layers.Dense(3, activation="relu", name="layer2"), layers.Dense(4, name="layer3"), ] )
ただし、sequential modelが適さない場合として、
などなどの場合には適さないようです。この場合は次の章で紹介するfunctional APIを使用します。
Creating a Sequential model
ここでは色々な方法でsequential modelを作成しています。
Pythonのリストのように、pop、addのようなメソッドで編集することもできるようです。
Specifyng the input shape in advance
keras.Inputオブジェクトを使うと、sequential modelを編集しながらsummaryメソッドでmodelの変数を確認することができるようになります。
A common debugging workflow: add() + summary()
summaryを確認しながらaddでlayerを追加してmodelを作成する例が紹介されています。
What to do once you have a model
model作成後の作業についてのリンクです。guide to multi-GPU and distributed trainingは実際に使う際にGPUの使い方で参考になるかもしれません。
Feature extraction with a Sequential model
中間層からの出力をアウトプットする方法が紹介されていますが、いまいち意図がわかっていません・・・Functional API modelを参考とのことです。
もしかしたら、中間層からの出力を使ってより複雑なmodelを作成することができるって言いたいのかもしれません。
Transfer learning with a Sequential model
特定のlayerの訓練を禁止する方法が紹介されています。また、すでに学習したmodelを使って新たなモデルを作る方法も紹介されています。
まとめ
sequential modelはKerasでmodelを作成する方法の一つで、一つのインプットを入力し一つのアウトプットを出力するlayerの単純な積み重ねのmodelを作成することができます。sequential modelと対になる概念がfunctional APIで、次の章で説明します。
The Functional API
Introduction
sequentialでも言及したように、functional APIはKerasでmodelを作る方法のもう一つの方法です。sequentialよりも複雑なトポロジーを持つmodelを作成することができます。
functional APIの使い方としては、以下のように、各layerを関数のように呼び出してtensorの計算を定めていきます。
inputs = keras.Input(shape=(784,)) dense = layers.Dense(64, activation="relu") x = dense(inputs) x = layers.Dense(64, activation="relu")(x) outputs = layers.Dense(10)(x) model = keras.Model(inputs=inputs, outputs=outputs, name="mnist_model")
Training, evaluation, and inference
訓練などにはcompile、fit、evaluateなどのメソッドが今までと同様に使えます。
Save and serialize
save()を呼び出せばmodelをシリアライズ化できます。詳しくはSave and load Keras modelsを見ましょう。
Use the same graph of layers to define multiple models
この例では、encoder_inputからencoder_outputを計算するencoderというmodelを作っていますが、さらに、encoder_outputを別のlayerの入力として使いdecoder_outputを計算しています。
出力の使い回しができる感じでしょうか。
All models are callable, just like layers
作成したmodelを別のモデルのlayerとして使用することもできるというお話ですね。
Manipulate complex graph topologies
Models with multiple inputs and outputs
こんな複雑なトポロジーを持つmodelも作れますよというお話。sequential modelではできません。

A toy ResNet model
ResNetのトポロジーも実現できますよというお話。これもsequential modelではできません。
Shared layers
同じlayerを使い回すこともできますよというお話。
Extract and reuse nodes in the graph of layers
中間層の出力もmodelの出力にできるというというお話ですかね?neural style transferをよく知りませんのであまり使い所が分かりませんが。
Extend the API using custom layers
Keralに用意されているlayer以外にも自作のlayerを作成してmodelを作ることができますよというお話です。詳しくはcustom layers and modelsを参照してください。
When to use the functional API
keras.Modelのサブクラス化とfunctional APIの使い分けについて解説しています。より詳しくはWhat are Symbolic and Imperative APIs in TensorFlow 2.0?
を参照してください。ここでは簡単な違いのみ紹介しています。
Functinal API strengths:
まず、作成が簡単という点が挙げられます。keral.Modelのサブクラス化はsuper(MLP, self).__init__(**kwargs)などを書かなければいけないので冗長なコードになります。
次にmodelの検証が簡単らしいです。functional APIは作成中にエラーがあれば随時気がつくことができるのでmodelができればちゃんと動くことが保証されるようなイメージでしょうか。
次に、ここでも見たように、中間layerの出力を確認することができます。
最後に、シリアライズ化することもできます。
Functional API weakness:
functional APIではトポロジーは有向非巡回グラフになるように定義しなければいけないようですが、これだとRNNの実装ができません。keras.Modelのサブクラス化だとRNNの実装ができるそうです。
Mix-and-match API styles
上で、modelの作成方法の優劣について説明しましたが、結局、それらは大した問題にはなりませんというお話です。
functional APIでもkeras.Modelのサブクラス化したmodelをlayerとして使えますし、その逆もできますというお話です。
まとめ
functional APIはmodelを作成する方法の一つで、
- sequential modelよりも柔軟なmodelを作ることができる
- シリアライズ化できる
keras.Modelのサブクラス化と使い分けてより良いmodelを作ることができる
などの特徴があります。
前の章で紹介したsequential modelがいつの間にかfunctional APIの下位互換になったような気がするのですが気のせいでしょうか・・・sequential modelの優位性って何かありましたっけ?
Training and evaluation with the built-in methods
Introduction
ここでは、Model.fit()、Model.evaluate()、Model.predict()の使い方を説明します。
この章はKerasの概要を掴むという意味ではやや高度な話なので飛ばすか、流し見でいいと思います。必要になったら戻ってきましょう。
より詳しいリンクもあるみたいですので、概要を掴んだ後に読んでみると良いでしょう。
API overview: a first end-to-end example
訓練のためにmodelに与えるデータは、メモリに乗り切るならNumPy arrayか、そうでなければtf.dataオブジェクトで渡します。
ここでのコードの例は
- function API でmodelを作って
- mnistデータの取得、前処理
compileでオプティマイザーと損失関数と評価指標の設定fitによる訓練historyによる訓練の履歴取得evaluateによる評価とpredictによる予測
をやっています。今までのおさらいの部分もあるでしょうがKerasによる訓練の流れをざっくり掴むことができます。
The compile() method: specifying a loss, metrics and an optimier
fitにより訓練するためにcompleでオプティマイザーと損失関数を指定する必要があります。評価指標は指定しなくても良いそうです。
Custom losses
損失関数を自作することもできます。y_trueとy_pred以外の引数を損失関数に渡したい場合はtf.keras.losses.Lossをサブクラス化して新しい損失関数のクラスを作成するようです。
Custom metrics
評価指標も自作できますよというお話です。
Handling losses and metrics that don't fit the standard signature
Handling losses and metrics that don't fit the standard signature
modelの重みなどにL2正則化を適用するなど、y_pred以外の値を損失関数に渡す場合はadd_lossメソッドを使うようです。
他にもいろいろ説明されているので余裕ができたら読みましょう。
Automatically setting apart a validation holdout set
訓練データ中の検証データの量を指定するvalidation_splitという引数が紹介されています。
Training & evaluation from tf.data Datasets
今まではmodelにNumPy arrayを渡す例を見てきましたが、ここからはtf.data.Datasetオブジェクト形式で渡す例を見ていきます。
より詳しくはtf.data documentationを参照しましょう。
tf.data.Datasetを使うと、
- 訓練集合のシャッフル
- バッチの指定
- 各エポックで使用するバッチの数
などを指定できるようになったりするそうです。
ただ、NumPy arrayの時はvalidation_splitが使えましたが、tf.data.Datasetの時は使えないようです。
Other input formats supported
modelへの入力として何を使えばいいか迷った際は
- データがメモリに載るくらい小さければNumPy array
- データが大きく、さらに並列で訓練したい場合は
Dataset - データが大きく、Python側で多くの前処理が必要な場合は
keras.utils.Sequence
を意識すると良いそうです。
Using a keras.utils.Sequence object as input
keras.utils.Sequenceの使い方が紹介されています。必要になったら読みましょう。
Using sample weighting and class weighting
サンプルやクラスに重みをつける方法が紹介されています。必要になったら読みましょう。
Passing data to multi-input, multi-output models
複数の入力や複数の出力を扱う場合の方法が説明されています。必要になったら読みましょう。
Using Callbacks
訓練中の特定のタイミングで指定した処理をする仕組みとしてcallbackが用意されています。例えば、早期終了をするcallbackがあります。
他にはcallbacks documentationを読みましょう。
また、callbackも自作できるようです。
Checkpointing models
比較的時間のかかる訓練の途中でcheckpointを保存する仕組みもあります。
詳しくはguide to saving and serializing Modelsを見ましょう。
Using learning rate schedules
訓練が進むにつれて学習率を減少させる機能も用意されているようです。
Visualizing loss and metrics during training
TensorBoardを使うと訓練中の様子を可視化することができるようです。
まとめ
この章ではより柔軟なmodelの構築や訓練の方法などを見ました。実際にKerasを使って複雑なmodelを作る際に参考になりそうです。
Making new Layers and Models via subclassing
この章はKerasの概要を掴むためにはやや高度なので飛ばしてもいいでしょう。必要になったら戻ってきましょう。
ただ、ModelとLayerの違いについてだけ確認しておきます。
The Model class
ModelクラスはLayerクラスと同じようなAPIを持っていますが、加えて以下の特徴があります:
- 訓練、評価、予測用の
model.fit、model.evaluate、model.predictメソッド - 内部のlayerを確認するための
model.layerメソッド - シリアライズ化するための
save、save_weightsメソッド
基本的には、内部的な処理はLayerを使い、それらをまとめて一つのmodelにするときにはModelを使うようです。
Save and load Keras models
この章ではmodelの保存について解説していますが、ひとまず以下のmodelの保存と読み込みを覚えておけばよさそうです。
- 保存:
model = ... # Get model (Sequential, Functional Model, or Model subclass) model.save('path/to/location')
- 読み込み
from tensorflow import keras model = keras.models.load_model('path/to/location')
Working with preprocessing layers
Keras preprocessing layers
Kerasには前処理をするためのLayyerが用意されています。
これらのLayerを使うことで生のデータをそのまま入力できるmodelを作ることができます。
Available preprocessing layers
ここでは、用途毎にさまざまな前処理layerが紹介されています。
残りの部分
この章の残りは必要になってから読めばいいでしょう。
Customize what happens in Model.fit
この章では、fitのオーバーライトをするようですが、高度な話なので必要になったら読めばいいでしょう。
Writing a training loop from scratch
この章では前の章よりもより深くmodelをカスタマイズするようです。これも必要になったら読めば良いでしょう。
終わり
TensorFlowのGuideを読んでみて、TensorFlowの概要を理解するために知っておけばいいと思った箇所は以上になります。
ただ、これ以外にも基本的なクラスはたくさんあります。それらは実際に使い始めて必要になったら読み返せばいいでしょう。